Jsoup
1.概述
Jsoup是一款基于 Java 的HTML解析器,它提供了一套非常省力的API,不但能直接解析某个URL地址、HTML文本内容,而且还能通过类似于DOM、CSS或者jQuery的方法来操作数据,所以 jsoup 也可以被当做爬虫]工具使用,从网站获取dom结构,从而解析下载数据。
- Document :文档对象。每份HTML页面都是一个文档对象,Document 是 jsoup 体系中最顶层的结构。
- Element:元素对象。一个 Document 中可以着包含着多个 Element 对象,可以使用 Element 对象来遍历节点提取数据或者直接操作HTML。
- Elements:元素对象集合,类似于List。
- Node:节点对象。标签名称、属性等都是节点对象,节点对象用来存储数据。
- 类继承关系:Document 继承自 Element(class Document extends Element) ,Element 继承自 Node(class Element extends Node)。
- 一般执行流程:先获取 Document 对象,然后获取 Element 对象,最后再通过 Node 对象获取数据。
1.引入依赖
在 Maven 项目的 pom.xml 中添加 Jsoup 依赖:
1
2
3
4
5
| <dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.15.3</version>
</dependency>
|
运行 HTML
2. 常用方法
2.1 解析 HTML
从 URL 加载网页:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class JsoupDemo {
public static void main(String[] args) throws Exception {
Document doc = Jsoup.connect("https://example.com")
.timeout(5000)
.userAgent("Mozilla/5.0")
.get();
System.out.println(doc.title());
}
}
|
从本地文件或字符串解析:
1
2
3
4
5
6
7
|
File input = new File("page.html");
Document doc = Jsoup.parse(input, "UTF-8");
String html = "<html><body><p>Hello Jsoup</p></body></html>";
Document doc = Jsoup.parse(html);
|
2.2 元素选择与提取
使用 CSS 选择器:
1
2
3
4
5
6
7
8
9
10
|
Elements links = doc.select("a[href]");
for (Element link : links) {
String href = link.attr("href");
String text = link.text();
System.out.println(text + " -> " + href);
}
Elements news = doc.select(".news-item");
|
提取数据示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
Elements images = doc.select("img[src]");
for (Element img : images) {
String src = img.attr("abs:src");
System.out.println("Image: " + src);
}
Element table = doc.select("table.data").first();
for (Element row : table.select("tr")) {
Elements cols = row.select("td");
if (cols.size() >= 2) {
String key = cols.get(0).text();
String value = cols.get(1).text();
System.out.println(key + ": " + value);
}
}
|
2.3 操作和修改 HTML
修改元素内容:
1
2
3
4
5
6
| Element div = doc.select("div.content").first();
div.text("New Content");
div.append("<p>Appended text</p>");
div.attr("class", "updated-content");
|
生成 HTML 字符串:
1
| String html = doc.html();
|
2.4 常用方法总结
通过标签、ID、类名获取元素
| 方法名 |
功能描述 |
示例代码 |
getElementById(String) |
通过 ID 获取 单个元素 |
Element header = doc.getElementById("main-header"); |
getElementsByTag(String) |
通过标签名获取 元素集合 |
Elements links = doc.getElementsByTag("a"); |
getElementsByClass(String) |
通过类名获取 元素集合 |
Elements newsItems = doc.getElementsByClass("news-item"); |
CSS 选择器
使用 select(String cssQuery) 方法,支持标准 CSS 选择器语法:
- 基础选择器
| 选择器类型 |
示例代码 |
解释 |
| 标签选择器 |
Elements divs = doc.select("div"); |
所有 <div> 元素 |
| ID 选择器 |
Element footer = doc.select("#footer"); |
ID 为 footer 的元素 |
| 类选择器 |
Elements buttons = doc.select(".btn"); |
所有类包含 btn 的元素 |
| 属性选择器 |
Elements imgs = doc.select("img[src]"); |
所有带有 src 属性的 <img> |
| 属性值匹配 |
Elements links = doc.select("a[href^=https]"); |
href 以 https 开头的链接 |
- 层级关系选择器
| 选择器类型 |
示例代码 |
解释 |
| 子元素选择器 |
Elements listItems = doc.select("ul > li"); |
直接子元素 <ul> 下的 <li> |
| 后代选择器 |
Elements paragraphs = doc.select("div.content p"); |
<div class="content"> 内的所有 <p> |
| 相邻兄弟选择器 |
Element nextDiv = doc.select("h1 + div"); |
紧接在 <h1> 后的 <div> |
| 后续兄弟选择器 |
Elements siblings = doc.select("h2 ~ p"); |
<h2> 之后的所有同级 <p> |
- 伪类选择器
| 选择器类型 |
示例代码 |
解释 |
:contains(text) |
Elements target = doc.select("p:contains(Hello)"); |
包含文本 Hello 的 <p> |
:matches(regex) |
Elements emails = doc.select("input:matches([\\w-]+@[\\w-]+\\.[\\w-]+])"); |
匹配邮箱格式的输入框 |
:not(selector) |
Elements nonLinks = doc.select("div:not(a)"); |
不包含 <a> 的 <div> |
3. 高级用法
3.1 处理表单与登录
1
2
3
4
5
6
7
8
9
10
11
| // 模拟登录(POST 请求)
Document loginPage = Jsoup.connect("https://example.com/login")
.data("username", "user123")
.data("password", "pass123")
.post();
// 携带 Cookie 访问受保护页面
Map<String, String> cookies = loginPage.connection().response().cookies();
Document profile = Jsoup.connect("https://example.com/profile")
.cookies(cookies)
.get();
|
3.2 过滤 XSS 攻击
1
2
3
| String unsafeHtml = "<script>alert('XSS');</script><p>Safe text</p>";
String safeHtml = Jsoup.clean(unsafeHtml, Whitelist.basic());
|
3.3 代理设置
1
2
3
| Document doc = Jsoup.connect("https://example.com")
.proxy("127.0.0.1", 8080)
.get();
|
4. 示例:抓取新闻标题和链接
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| public class NewsCrawler {
public static void main(String[] args) {
try {
Document doc = Jsoup.connect("https://news.example.com")
.timeout(10000)
.get();
Elements newsItems = doc.select(".news-list li");
for (Element item : newsItems) {
String title = item.select("h2.title").text();
String link = item.select("a").attr("abs:href");
System.out.println(title + " - " + link);
}
} catch (IOException e) {
System.err.println("抓取失败: " + e.getMessage());
}
}
}
|
仿苏宁搜索
实现步骤:
- 浏览器抓取苏宁易购首页前端源码保存到本地
- 使用Jsoup根据关键词爬取苏宁商品信息存入es中
- 使用ElasticsearchRestTemplate根据关键词实现搜索功能
es文档类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| @Data
@Setting(settingPath = "goods-setting.json")
@Document(indexName = "goods")
public class GoodsDoc {
@Id
private String id;
@Field(type = FieldType.Keyword,index = false)
private String image;
@Field(type = FieldType.Double,index = false)
private Double price;
@Field(
type = FieldType.Text,
analyzer = "text_analyzer",
searchAnalyzer = "ik_smart",
copyTo = "fullText"
)
private String title;
@Field(type = FieldType.Keyword,copyTo = "fullText")
private String store;
@Field(type = FieldType.Text,analyzer = "ik_max_word")
private String fullText;
@CompletionField(analyzer = "completion_analyzer")
private Completion suggest;
}
|
1.数据爬取
接口
1
2
3
4
| @RequestMapping("/load")
public void load(String label) throws IOException {
indexSearchService.load(label);
}
|
service
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| public void load(String keyword) throws IOException {
ThreadUtil.safeSleep(3000);
String url = String.format("https://search.suning.com/%s/", keyword);
Document doc = Jsoup.connect(url)
.timeout(10000)
.get();
Elements products = doc.select(".product-box");
for (Element productBox : products) {
Element hiddenInput = productBox.selectFirst(".hidenInfo");
String dataPro = hiddenInput.attr("datapro");
String goodsId = dataPro.replace("||", "");
String title = productBox.selectFirst(".title-selling-point a").text().trim();
String imageUrl = productBox.selectFirst(".res-img img").attr("abs:src");
String store = productBox.selectFirst(".store-stock a").text();
GoodsDoc goodsDoc = new GoodsDoc();
goodsDoc.setId(goodsId);
goodsDoc.setTitle(title);
goodsDoc.setImage(imageUrl);
goodsDoc.setStore(store);
Random random = new Random();
double d = random.nextDouble() * 2000;
BigDecimal bigDecimal = new BigDecimal(d);
double price = bigDecimal.setScale(2, RoundingMode.HALF_UP).doubleValue();
goodsDoc.setPrice(price);
boolean exists = template.exists(goodsId, GoodsDoc.class);
log.info("商品id:{},是否存在{}", goodsId, exists);
goodsDoc.setSuggest(buildSuggest(title, store));
if (exists) {
continue;
}
template.save(goodsDoc);
}
}
|
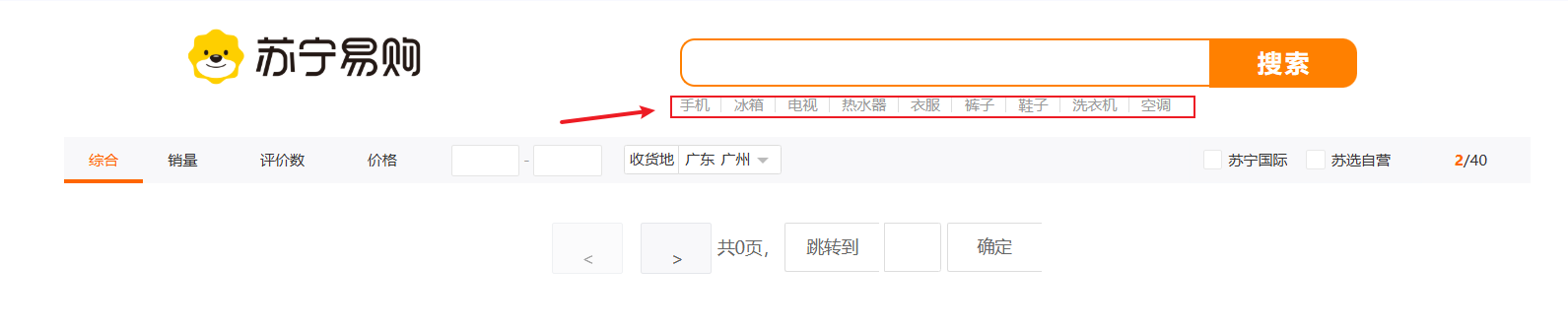
通过点击标签页加载数据到es数据库中
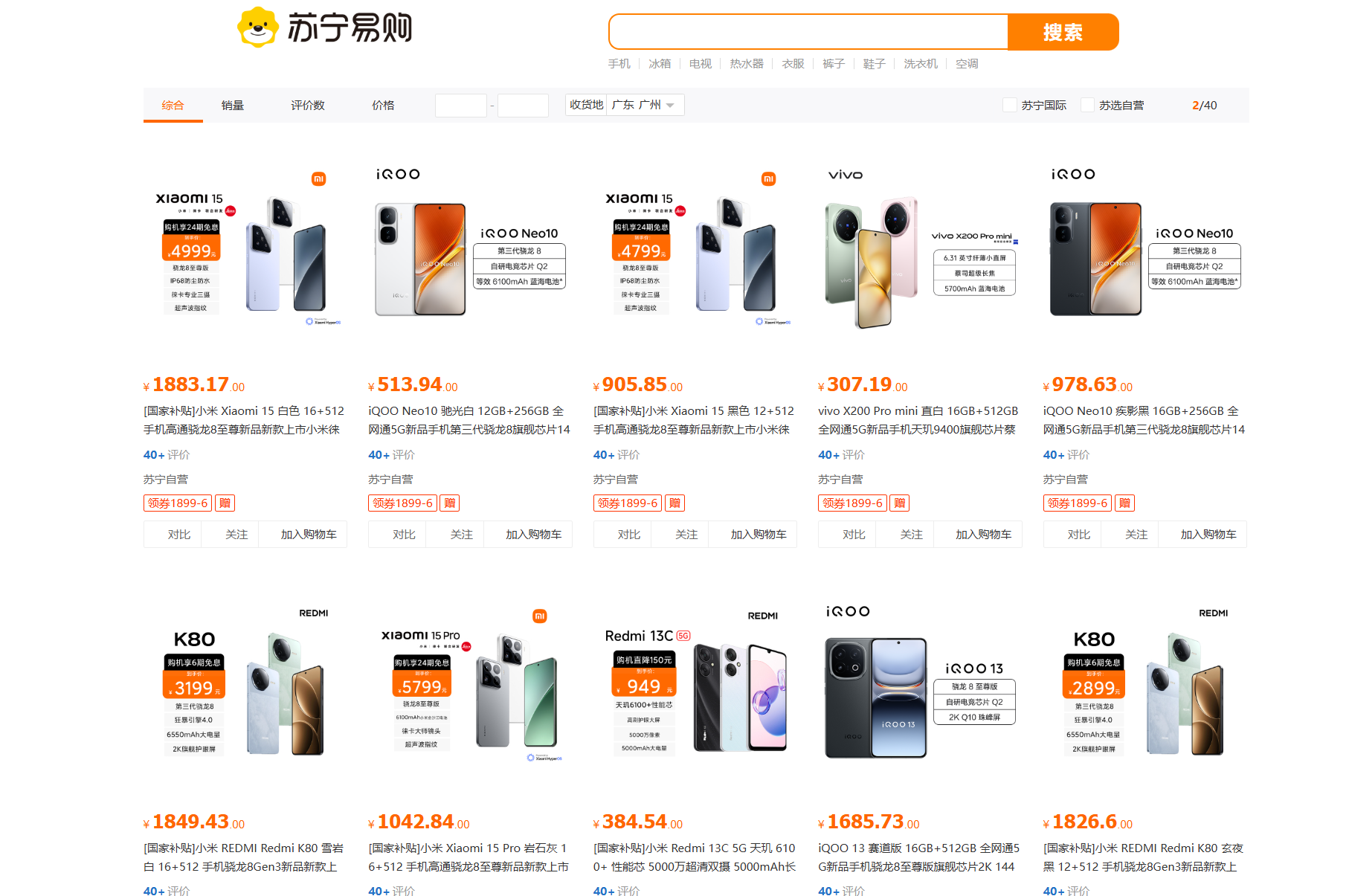
2.关键词搜索
接口
1
2
3
4
| @PostMapping
public PageResult search(@RequestBody RequestParams params) {
return indexSearchService.search(params);
}
|
RequestParams
1
2
3
4
5
6
7
| @Data
public class RequestParams {
private String keyword;
private Integer pageNo;
private Integer pageSize;
private String sortBy;
}
|
PageResult
1
2
3
4
5
6
7
| @Data
@AllArgsConstructor
@NoArgsConstructor
public class PageResult {
private Long total;
private List<GoodsDoc> goods;
}
|
service
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| public PageResult search(RequestParams params) {
int pageNo = params.getPageNo() - 1;
Pageable pageable = PageRequest.of(pageNo, params.getPageSize());
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder()
.withPageable(pageable);
if (!StringUtils.hasText(params.getKeyword())){
NativeSearchQuery query = queryBuilder.withQuery(QueryBuilders.matchAllQuery())
.withPageable(PageRequest.of(pageNo, params.getPageSize()))
.build();
SearchHits<GoodsDoc> searchHits = template.search(query, GoodsDoc.class);
List<GoodsDoc> goodsDocs = searchHits.stream()
.map(SearchHit::getContent)
.collect(Collectors.toList());
return new PageResult(searchHits.getTotalHits(), goodsDocs);
}
NativeSearchQuery query = queryBuilder
.withQuery(QueryBuilders.matchQuery("title", params.getKeyword()))
.withPageable(PageRequest.of(pageNo, params.getPageSize()))
.withHighlightFields(new HighlightBuilder.Field("title")
.preTags("<span style='color:red'>")
.postTags("</span>"))
.build();
SearchHits<GoodsDoc> searchHits = template.search(query, GoodsDoc.class);
List<GoodsDoc> goodsDocs = searchHits.stream().map(hit -> {
GoodsDoc goodsDoc = hit.getContent();
if (hit.getHighlightFields().containsKey("title")) {
goodsDoc.setTitle(hit.getHighlightFields().get("title").get(0));
}
return goodsDoc;
}).collect(Collectors.toList());
return new PageResult(searchHits.getTotalHits(), goodsDocs);
}
|
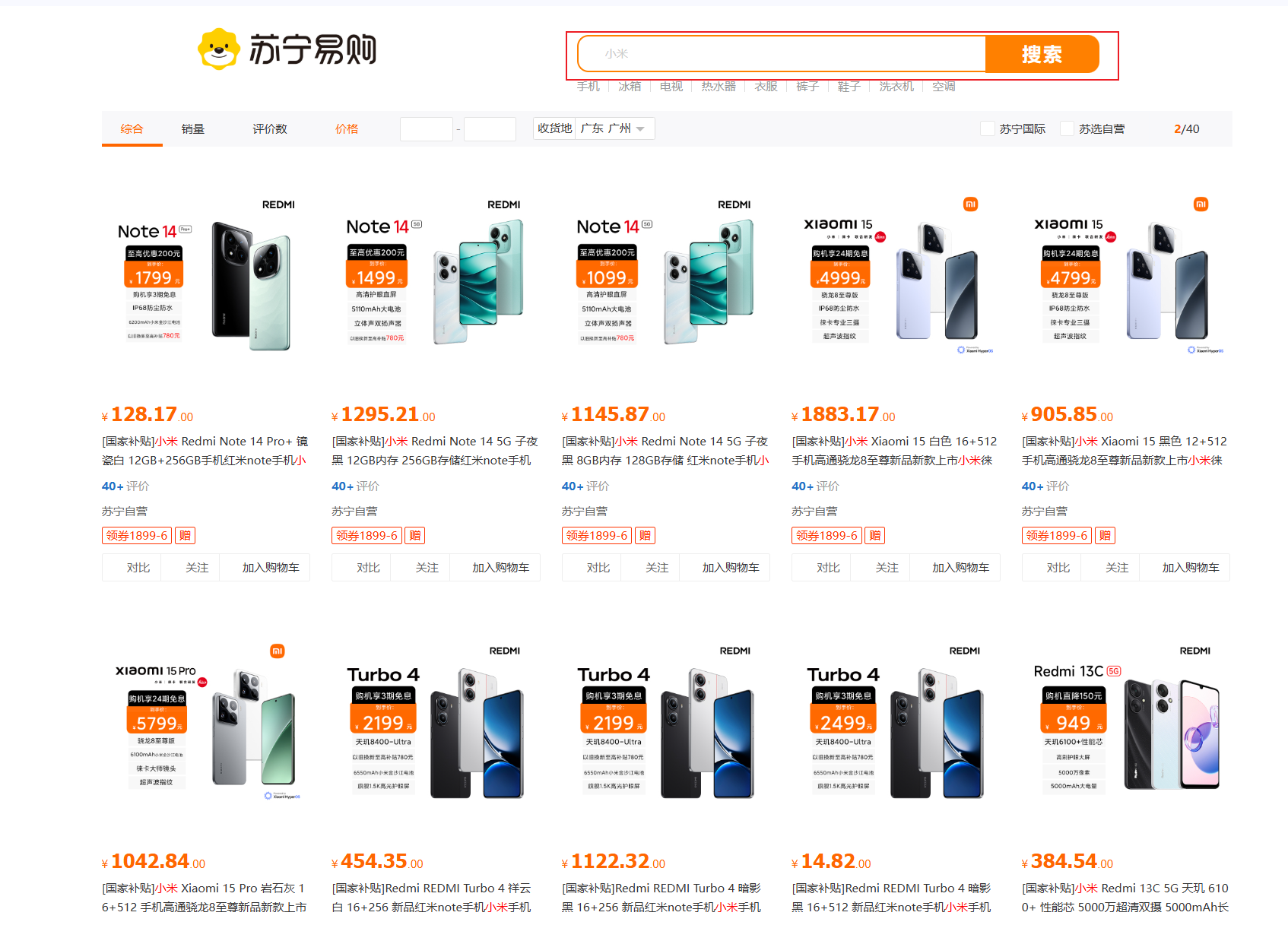
3.自动补全
接口
1
2
3
4
| @GetMapping("/suggest")
public List<String> suggest(String prefix) {
return indexSearchService.suggest(prefix);
}
|
service
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| public List<String> suggest(String prefix) {
if (!StringUtils.hasText(prefix)){
return Collections.emptyList();
}
CompletionSuggestionBuilder suggestionBuilder = new CompletionSuggestionBuilder("suggest")
.prefix(prefix)
.skipDuplicates(true)
.size(10);
SuggestBuilder s = new SuggestBuilder().addSuggestion("goods_suggest", suggestionBuilder);
SearchResponse response = template.suggest(s, GoodsDoc.class);
Suggest suggest = response.getSuggest();
return suggest.getSuggestion("goods_suggest").getEntries().stream()
.flatMap(entry -> entry.getOptions().stream())
.map(option -> option.getText().toString())
.collect(Collectors.toList());
}
|
es配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| {
"analysis": {
"analyzer": {
"text_analyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
},
"completion_analyzer": {
"tokenizer": "keyword",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_separate_first_letter": true,
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
}
|
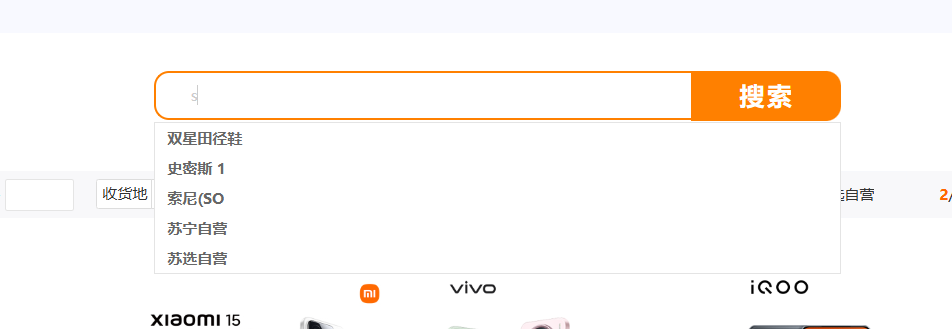
4. 其他功能实现
完善中……..
 微信
微信 支付寶
支付寶